What is AIConfig
AIConfig is a source-control friendly way to manage your prompts, models and model parameters as configs. It allows you to store and iterate on generative AI model behavior separately from your application code.
What problem it solves
Today, application code is tightly coupled with the gen AI settings for the application -- prompts, parameters, and model-specific logic is all jumbled in with app code.
- results in increased complexity
- makes it hard to iterate on the prompts or try different models easily
- makes it hard to evaluate prompt/model performance
AIConfig helps unwind complexity by separating prompts, model parameters, and model-specific logic from your application.
- simplifies application code -- simply call
config.run() - open the
aiconfigin a playground to iterate quickly - version control and evaluate the
aiconfig- it's the AI artifact for your application.
Anatomy of AIConfig
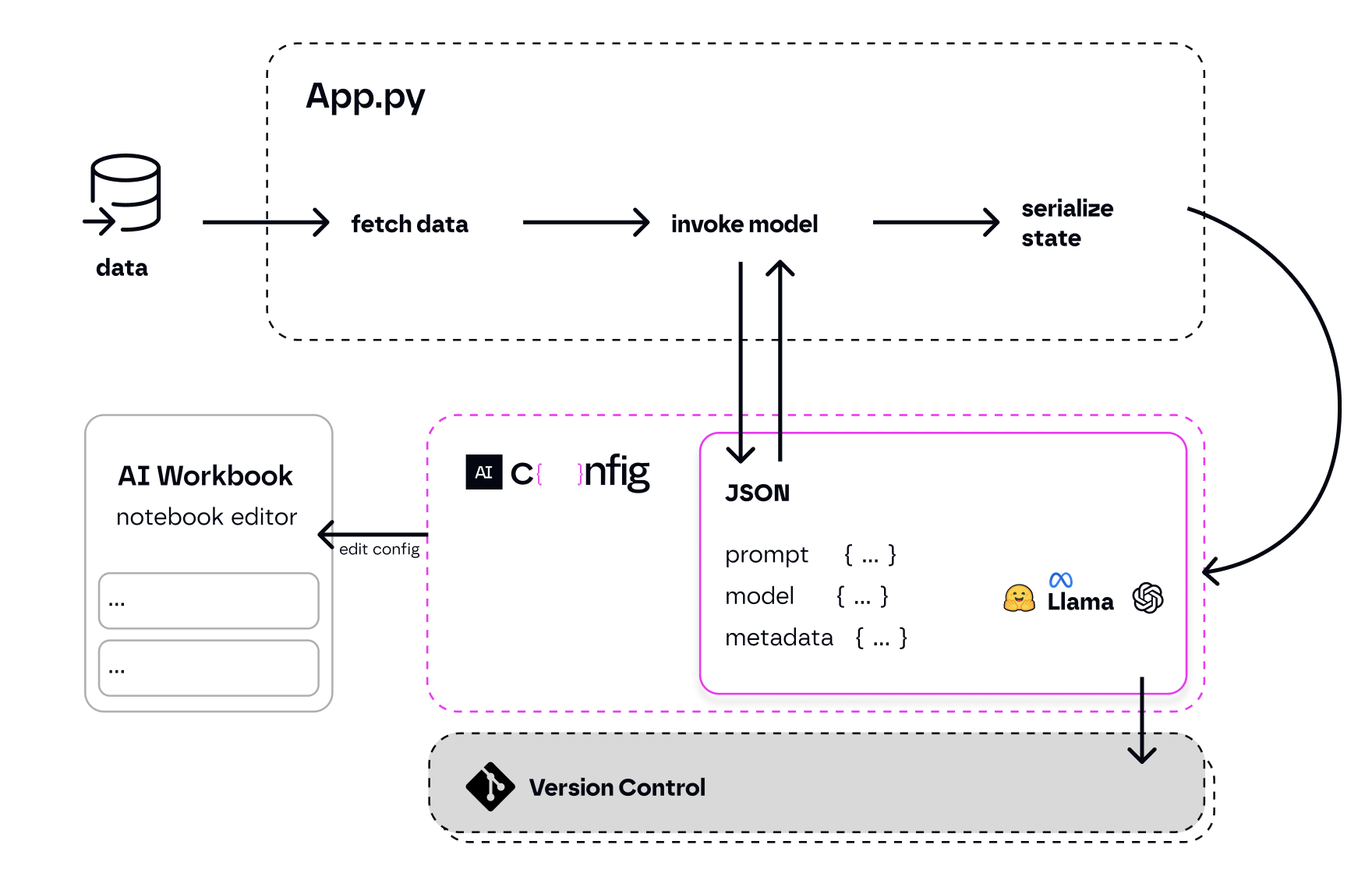
aiconfigfile format: a standardized JSON format to store generative AI model settings, prompt inputs and outputs, and flexible multi-purpose metadata.- AIConfig SDK: Python and Node SDKs to use
aiconfigin your application code, and extension points to customize behavior. - AI Workbook editor: A notebook-like playground to edit
aiconfigfiles visually, run prompts, tweak models and model settings, and chain things together.
AIConfig is multi-modal and model-agnostic. This enables powerful interop between different models and modalities, including chaining them together (see prompt chaining). For example, a Whisper (speech-to-text) prompt can be connected to a GPT4-V prompt (image+text-to-text) to build complex AI applications, all backed by the same aiconfig serialization format.
Prompts as configs
Unlike traditional predictive ML development undertaken largely by ML researchers, generative AI applications are being developed collaboratively by software engineers.
Separating prompt management from application development leads to a few powerful consequences:
- Separation of concerns: You can iterate on prompts and models separately from application code -- and different people could be responsible for them, making the overall development more collaborative.
- Notebook editor for prompts: Having prompts and models in one place allows a notebook-like editor environment to iterate on the aiconfig. This greatly increases the velocity of prototyping and iteration.
- Governance: As a source-controlled artifact,
aiconfigcan be used for reproducability and provenance of the generative AI bits of your application.
Using AIConfig
See the Getting Started guide for a more detailed overview, and spend time getting familiar with the aiconfig file format.
Here are the basics of interacting with aiconfig:
- Create an AIConfig from scratch
- Run a prompt
- Pass data into prompts
- Prompt chains
- Callbacks and monitoring
Guides
There is a lot you can do with these capabilities. We have several tutorials to help get you started:
Improved AI Governance
aiconfig helps you track the signature of generative AI model behavior:
- prompt and prompt chains that constitute the input
- model to run inference (can be any model from any model provider)
- model parameters to tune the model behavior
- outputs cached from previous inference runs, which can be serialized optionally.
Having a dedicated source-controlled artifact for generative AI helps with reproducibility, evaluation and rapid iteration. You can iterate on this artifact, evaluate it and integrate it into the rest of your application development workflow.
Extensibility
AIConfig is meant to be fully customizable and extensible for your use-cases. The specific parts that you can customize include:
- Model Parsers: these parsers are responsible for deciding how to run inference, what data to store in the
aiconfig, and how. You can add model parsers for any model of any input/output modality, and from any provider (including a model running on your local machine). - Callbacks: callback handlers allow you to hook up
aiconfigruns to monitoring and observability endpoints of your choosing. - EvaluationComing Soon: define custom evaluators and run batch evaluation to measure the performance of your
aiconfig. - RoutingComing Soon: define custom routers over a series of
aiconfigs to intelligently route incoming requests over prompts and models (i.e. prompt routing and model routing).